Blog Tackling the Top 4 Data & Analytics Challenges With Databricks
By Todd Walker / 16 Jun 2021 / Topics: Cloud Analytics Data and AI
By Todd Walker / 16 Jun 2021 / Topics: Cloud Analytics Data and AI

The ability to properly harness the power of data and analytics can lead to the success or failure of an organization. Businesses of every size are investing in modern data platforms to create insights, make predictions and prescribe intelligent actions to build competitive advantages and improve relevancy in today’s environment.
Although many organizations are investing in data scientists, data engineers and data architects while building data solutions such as data warehouses, data lakes and business intelligence tools, many are struggling to achieve their goals. In fact, Gartner predicts that only one in five analytics projects will successfully deliver the expected business outcomes in the next several years.
So, why do so many analytics projects fail?
Many failures can be attributed to gaps in leadership, organizational culture and skill sets. But the reality is, even with these elements in place, the solutions themselves remain difficult to implement. Choosing the right architecture and tooling from day one is critical to success.
Oftentimes, organizations will kick off a data and analytics project only to discover their data architecture is a mess — with multiple siloed systems, lots of data movement and poor data quality. They may attempt to solve these problems with expensive solutions, cobbling together multiple open-source technologies which only make these systems harder to maintain and secure.
Luckily, there’s a smarter, simpler alternative to this complexity: introducing Databricks and the Lakehouse architecture.
Databricks provides a single, unified data platform that allows data scientists, data analysis and data engineers to seamlessly collaborate and provide real business outcomes with data. The cloud-based platform is available on all three major public clouds: Azure, AWS and Google Cloud Platform (GCP). With organizational DNA originating from the creators of Apache Spark, the Databricks solution serves as a scalable, open platform designed to handle even the most challenging data needs while integrating with other solutions and avoiding vendor lock in.
Databricks enables the implementation of what has become known as the Lakehouse architecture. Gone are the days where it’s necessary to have separate solutions for data analytics, data science and streaming. Now, this can all be achieved on a single platform.
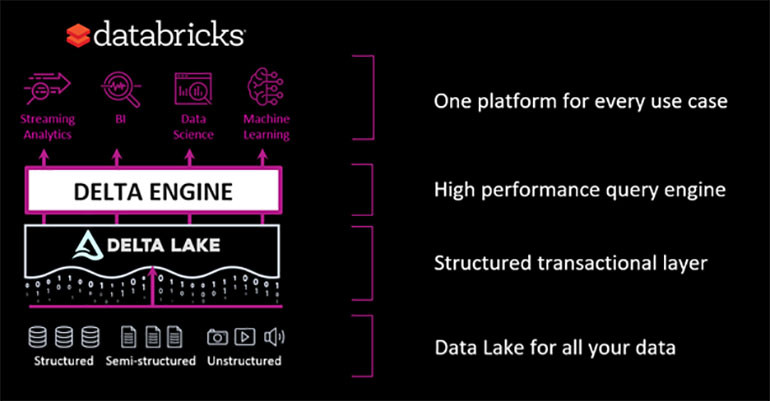
There are several key technologies built into the Databricks platform that enable this architecture.
The Databricks platform, along with the Lakehouse architecture, is a key component of an effective data analytics strategy — providing the tools to overcome four of the biggest challenges standing in the way of success.
Having accessible, high-quality data, with the ability to scale, is the foundation of any modern data platform. If you don’t get the data right, then any workload that you place on top of it is likely to fail.
The first step on the platform is to get the data organized so it can be easily accessed by anyone needing it for their use case. This is accomplished by placing the data in a data lake and permissioning the data out as necessary for various teams and use cases. New data must be added quickly and easily while ensuring the consistency and quality of the data. This helps break down siloes and provides analysts and scientists with a consistent and trusted platform on which to build their solutions.
If accessing the data is tedious and slow, the platform will not be useful. As datasets continue to grow in size and granularity, analysts require a high-performing environment to work at any scale against any type of data.
Databricks helps makes all this possible with Delta Lake. By supporting ACID transactions at scale, Delta Lake reduces friction for engineers as they process and make data available. It increases reliability to enforce schemas while giving options to handle schema drift. Finally, it offers the capabilities to optimize and tune query performance to meet the demands of modern analysts. As an open technology, organizations can be assured that the data can be accessed in the right way, by the right solution, for any use case.
Succeeding as an organization utilizing Machine Learning (ML) and Artificial Intelligence (AI) is much more complicated than hiring a team of data scientists to build models. Supporting data scientists and operationalizing models often involve complicated solutions to support the following:
Databricks streamlines and supports all these processes — allowing your data scientists and MLOps engineers to focus on the models.
With MLFlow, Databricks simplifies the entire ML lifecycle from model development to deployment to production. MLFlow includes a tracking server to track the models and parameters used on every experiment, providing valuable insights to determine the best models and features. With the integration of Delta Lake’s time travel capability, it’s simple to validate exactly what data produced which model. MLFlow’s registry server also simplifies model deployment by using approval workflows and allowing the model to be deployed and referenceable to scoring processes.
In addition to MLFlow, Databricks recently announced the release of AutoML. This tool enables data scientists to provide data, tell the system what it’s trying to predict and ask the system to make its own predictions and feature development. Once complete, the data scientist will be presented with multiple models and a recommendation of the best option. This can be used to validate whether a dataset can feasibly make a prediction or simply to jump start data science work. The scientist will also be able to see all the notebooks used to create the model. Not only does this create transparency, but it can also give data scientists a head start on model development, saving valuable time on a project.
Another recent announcement from Databricks is the Feature Store. Much of the work data scientists perform comes down to generating transformations to aggregate and calculate values in order to make predictions. These are often rebuilt and reused inside the organization on other projects and during production scoring. The Feature Store can simplify this process by making features more discoverable and reusable. These capabilities were built with MLFlow and Delta Lake in mind to facilitate versioning and lineage.
Databricks also provides specific runtimes for machine learning. In addition to Spark, this includes common frameworks for data science such as Tensorflow and Pytorch. As an open platform, scientists can source from a large ecosystem of other libraries to integrate into their experiments.
Most Business Intelligence (BI) workloads are restricted to a fraction of the data that an organization collects. Most of these are done against data warehouses which aggregate and transform data for specific use cases. This can be great for a lot of common reporting and known analysis, but it can also restrict an organization’s ability to form new and valuable insights.
To solve this challenge, Databricks and the Lakehouse architecture provide the ability to “write once and access anywhere.” Delta allows for excellent performance without the need to resort to moving the data out and into a separate warehouse platform. While you can include a purpose-built data model, the user can also access all organizational data, regardless of if it’s modeled, to find new insights.
As an open platform, it’s accessible to a wide variety of platforms from Databricks’ own Databricks SQL, to Power BI, Looker, Tableau, Synapse and many other platforms.
When bringing in one or more data platforms, it can be challenging to make sure that the platform is fully compliant with all internal and government regulations (HIPPA, GDPR, CCPA, etc.). Fortunately, Databricks has you covered when it comes to security and compliance.
Databricks integrates natively with the security infrastructure of Azure, AWS and GPC. It integrates with your chosen identify provider, whether it’s Active Directory, Okta or Ping. These integrations allow you to easily control who can access your data and to what degree.
Databricks also allows you to encrypt your data natively or bring your own key. It can be injected into your own networks to provide fine-grain controls for how your data moves and how it’s accessed.
Finally, native features of Delta Lake make it easy to clean up Personally Identifiable Information (PII) data in order to comply with privacy regulations.
It’s an exciting time to be working on Data & AI projects. While there may be a lot of risk and pressure to succeed, Databricks is making it easier to overcome the most common obstacles and accelerate time to value. Whether tackling a BI workload, data science platform or (as is increasingly the case) supporting both, Databricks is well positioned to provide that elusive success by mitigating your biggest challenges.

Data Solutions Practice Manager, Insight
Todd is a national architect for Insight’s Digital Innovation team. He’s passionate in pursuing a data-centric solutions and decision-making. He has a background across the entire Data & AI spectrum, and he specializes in cloud-based solutions.